FP-Growth 演算法(Frequent Pattern Growth Algorithm)
摘要
FP-Growth 演算法是一種高效的頻繁項目集挖掘方法,可以應對更大型交易資料集,避免像是 Apriori 演算法多次生成候選集與全資料掃描的低效。
FP-Growth 演算法以 壓縮樹狀結構(FP-tree) 保存交易資料中項目之間的共現(co-occurrence)關係,並透過 遞迴模式成長(pattern growth) 直接挖掘所有頻繁項目集。
對於壓縮樹狀結構可以理解成,原先樹在最不理想的狀態下,可以展開所有的組合,但是當資料一據頻繁項目進行排序時,樹的結構則呈現特定頻繁項目的組合。
介紹
FP-Growth 的目標是找出所有支持度大於支持度門檻的項目,該項目集合為頻繁項目集,透過建立 FP-tree,將多筆交易中重疊的項目前綴(Prefix)合併壓縮,以減少冗餘計算,並透過條件模式基與條件 FP-tree 遞迴生成頻繁模式
下圖示意樹結構壓縮的原理,如果當一個資料集的項目以隨機順序排列,那麼最壞的情況,該樹狀結構可能展開為所有的組合,而當項目依據頻繁度排序後,樹的分支將重疊共用,形成具壓縮性的結構。

方法論
1. 計算項目頻率(Item Frequency)
計算每個項目在交易資料集中的出現次數,僅保留支持度(Support)≥ minsup 的項目。
此步驟確定哪些項目為頻繁項目,當 minsup=4 ,計算每個單獨項目是滿足成為頻繁項目的條件。
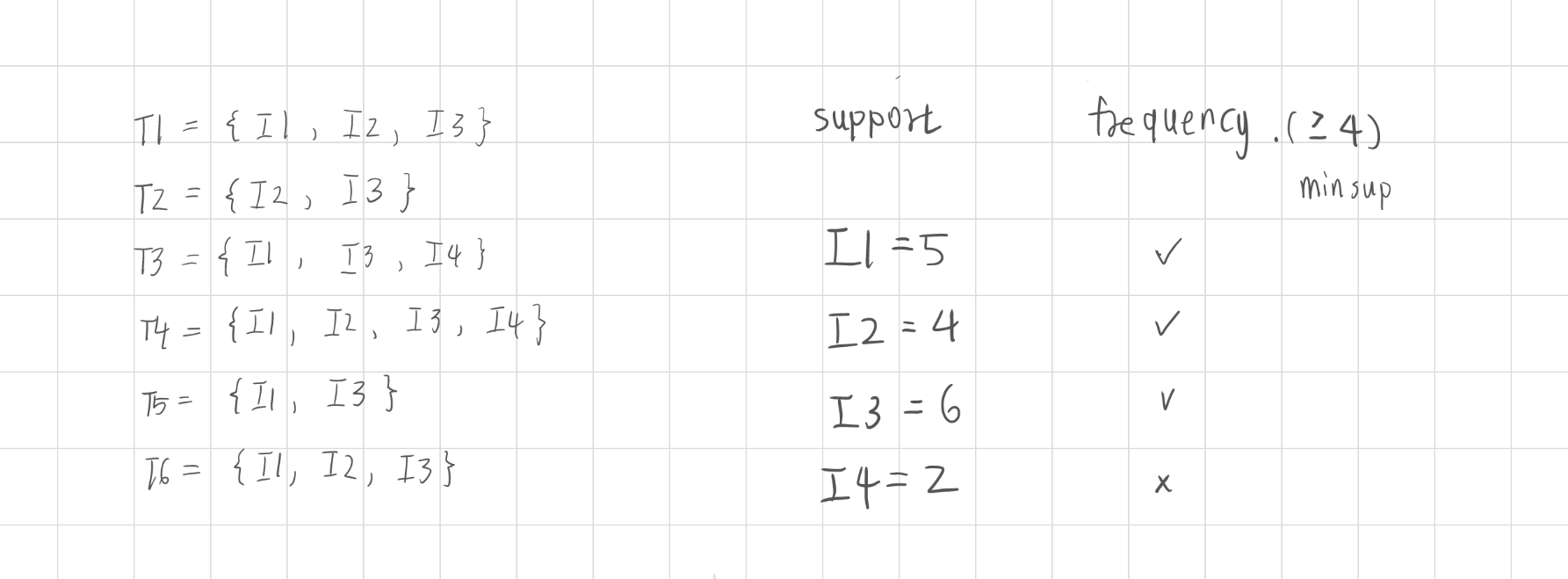
2. 頻率排序(Frequency Ordering)
將項目依全域頻率(Global Frequency)由高到低排序,每筆交易中的項目依此順序排列。
此排序可讓共享前綴的交易合併,減少 FP-tree 節點結構冗餘。
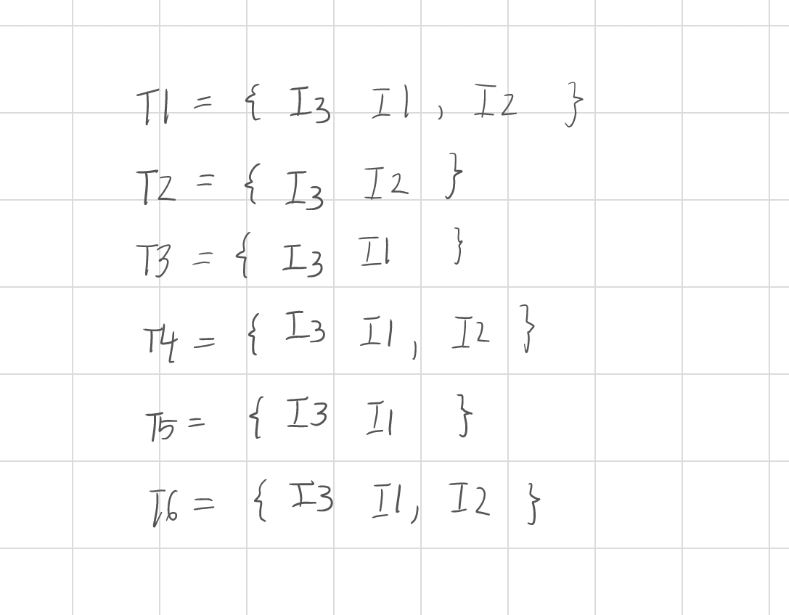
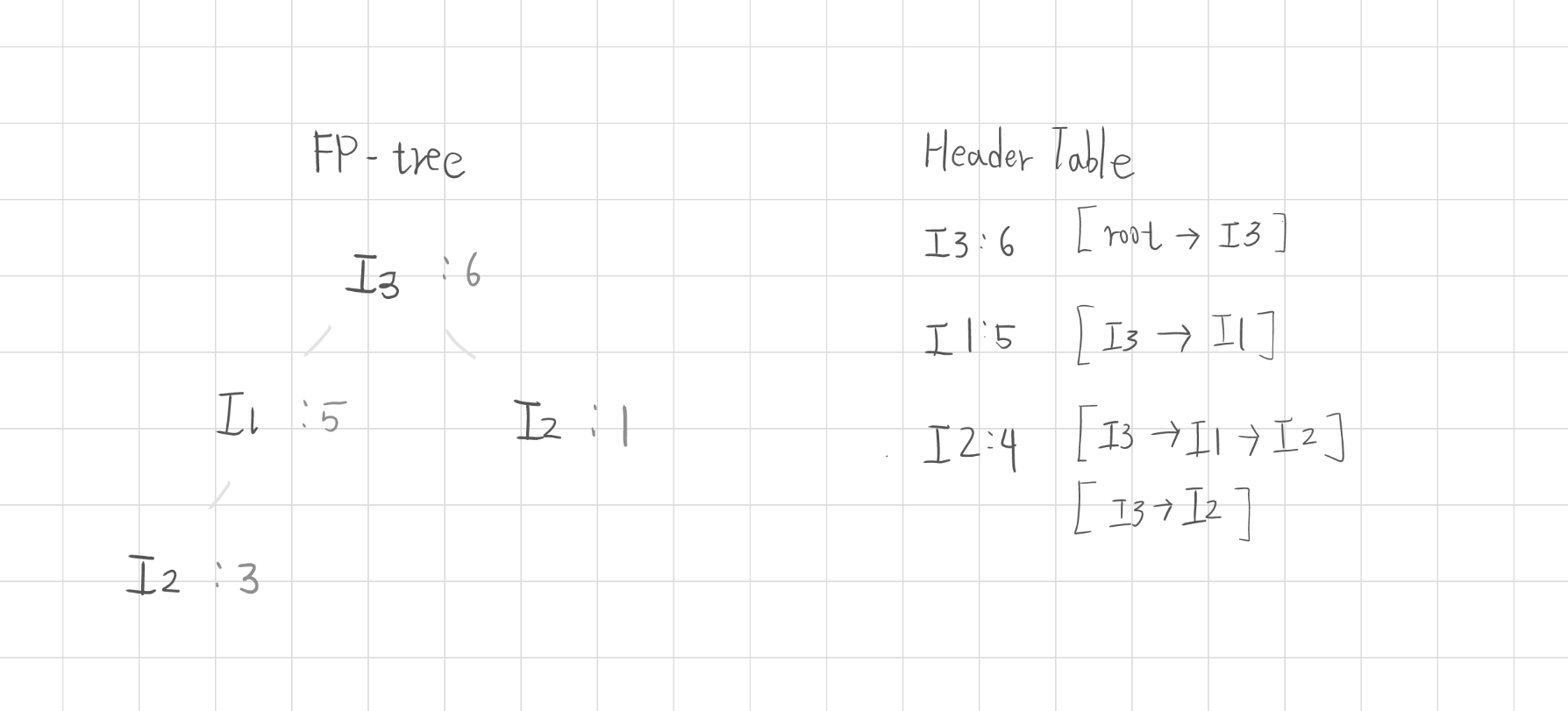
3. FP-tree 建構(FP-tree Construction)
FP-tree(Frequent Pattern Tree)用來壓縮交易資料並保留頻率資訊,並且建立項目索引表(Header Table),項目索引表可以用來紀錄錄每個頻繁項目的總出現次數,並連結至樹中對應節點的位置
-
將每筆交易依排序後的項目插入樹中:
-
若前綴分支存在 → 節點計數累加
-
否則建立新節點
-
同時維護 Header Table,連結相同項目的節點
4. 條件模式基(Conditional Pattern Base)
條件模式基用於收集某基準項目(後綴,Suffix)的頻繁前綴(Prefix)資訊:

-
對每個基準項目,取出包含該項目的所有路徑
-
擷取每條路徑上方的前綴節點(Prefix)及其計數
-
條件模式基提供該項目的局部資料,供建立條件 FP-tree 使用
5. 條件 FP-tree(Conditional FP-tree)
條件 FP-tree 是從條件模式基建構的局部 FP-tree:

-
節點僅保留支持度 ≥ minsup 的項目
-
用於遞迴挖掘基準項目的頻繁模式
-
節點計數直接提供支持度,避免重新掃描原始交易集
6. 模式成長(Pattern Growth)
模式成長是 FP-Growth 的核心步驟,用於從 條件 FP-tree(Conditional FP-tree) 中遞迴生成所有頻繁項目集(Frequent Itemsets)。
對每個頻繁項目(基準項目,Suffix Item)建立對應的條件 FP-tree,並以遞迴方式將 前綴(Prefix) 與 後綴(Suffix) 結合,逐層擴展出新的頻繁模式。
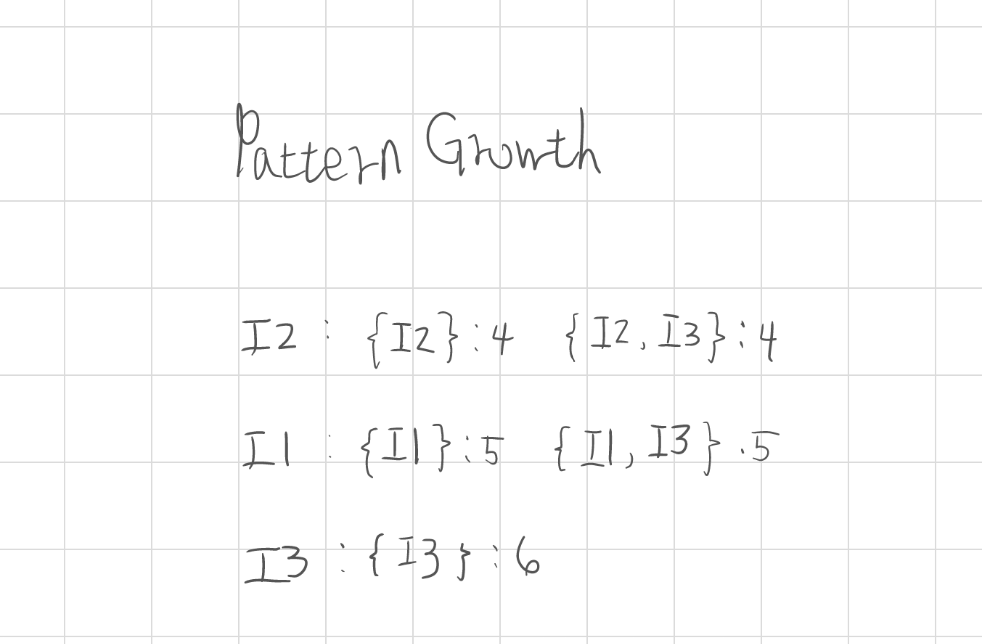
此步驟遞迴完成後,即可得到所有滿足最小支持度的頻繁模式。
演算法應用
FP-Growth 廣泛應用於:
-
購物籃分析(Market Basket Analysis)
-
推薦系統(Recommendation Systems)
-
關聯規則挖掘(Association Rule Mining)